Learning
Biologically-Inspired Learning for Humanoid Robots(BiLHR)
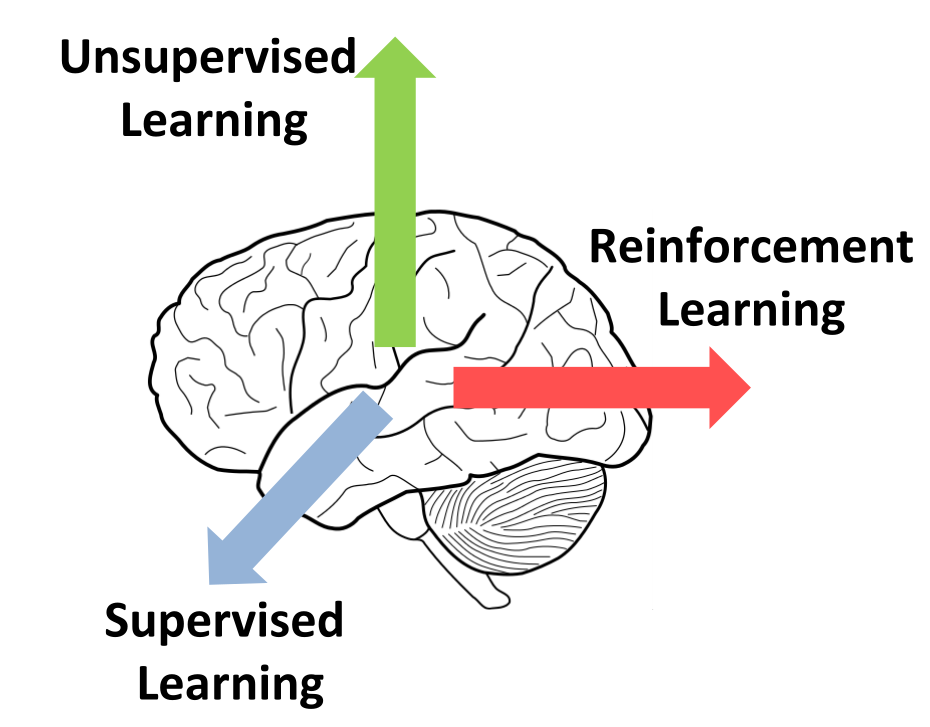
Handle three types of learning via human brain.
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
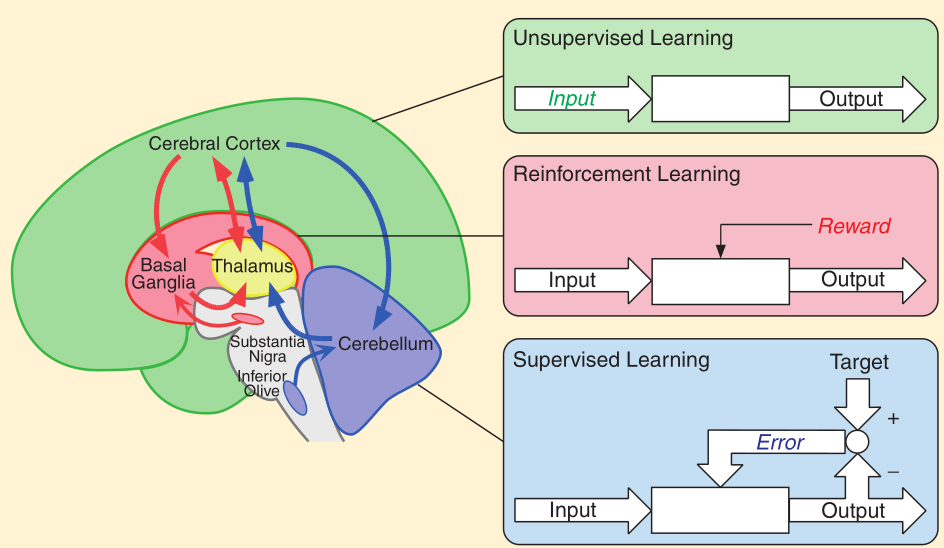
Supervised Learning
A type of learning is inferring a model from labelled training data. It requires the explicit provision of input-output pairs. Supervised learning occurs by constructing a mapping from input to the output pairs.

2D data supervised learning beteween vision(X, Y) and motors(Sholder).
Unsupervise Learning
A type of learning refers to the problem of trying to find hidden structure in unlabelled data. It has no concept of target data. Unsupervised learning performs processing only on the input data.
Reinforcement Learning
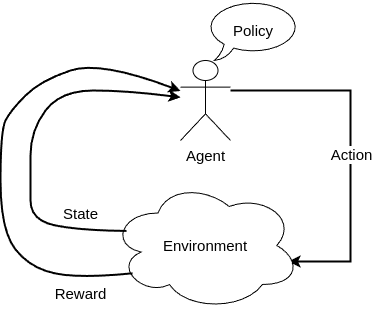
A type of learning is considered a hybrid of supervised and unsupervised learning. It simulates the human learning based on trial and error. RL uses a scalar reward signal to evaluate input-output pairs and hence discover, through trial and error, the optimal ouputs for each input.
Approximate Dynamic Programming and Reinforcement Learning(ADPRL)
The course focused on the theoretical aspects of reinforcement learning. It covered topics ranging from decision-making, deterministic and stochastic processes, and Markov Decision Processes (MDPs) to Bellman Equations and Operators, Dynamic Programming (DP), Q-learning, Monte Carlo methods, and Temporal Difference learning. ADPRL did not include deep learning concepts due to organizational reasons. In essence, deep reinforcement learning (DRL) replaces the mapping from state to action with a neural network. I will explore the theoretical components of reinforcement learning in more detail later.
Applied Reinforcement Learning(ARL)
ARL focused on the application of reinforcement learning from scratch. Unlike ADPRL, it concentrated on building an RL algorithm based on a game called “Hexball.” The use of neural networks was prohibited for this project. Instead, we designed our own reinforcement learning approach, primarily using Q-learning, and implemented it in C++.
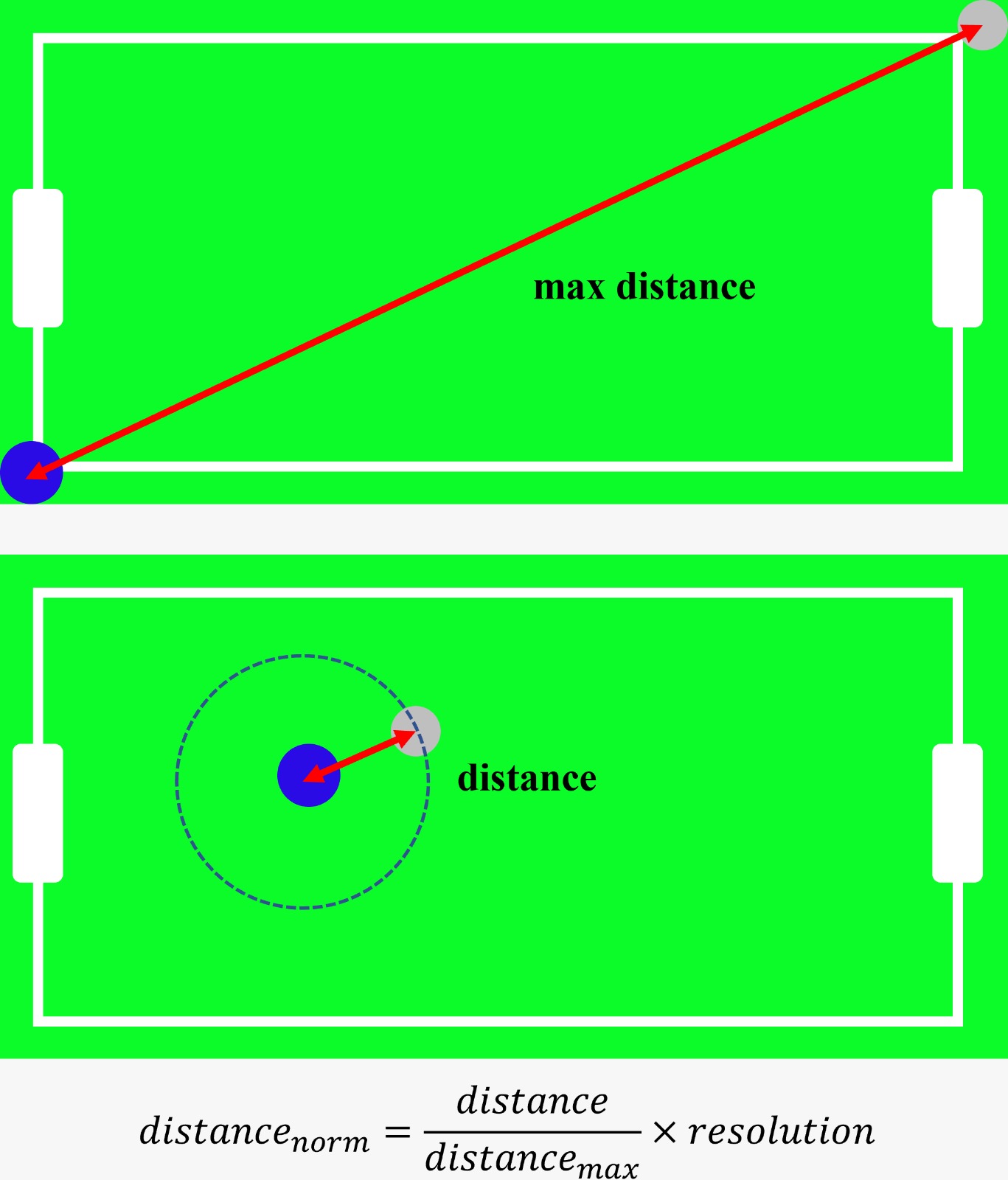
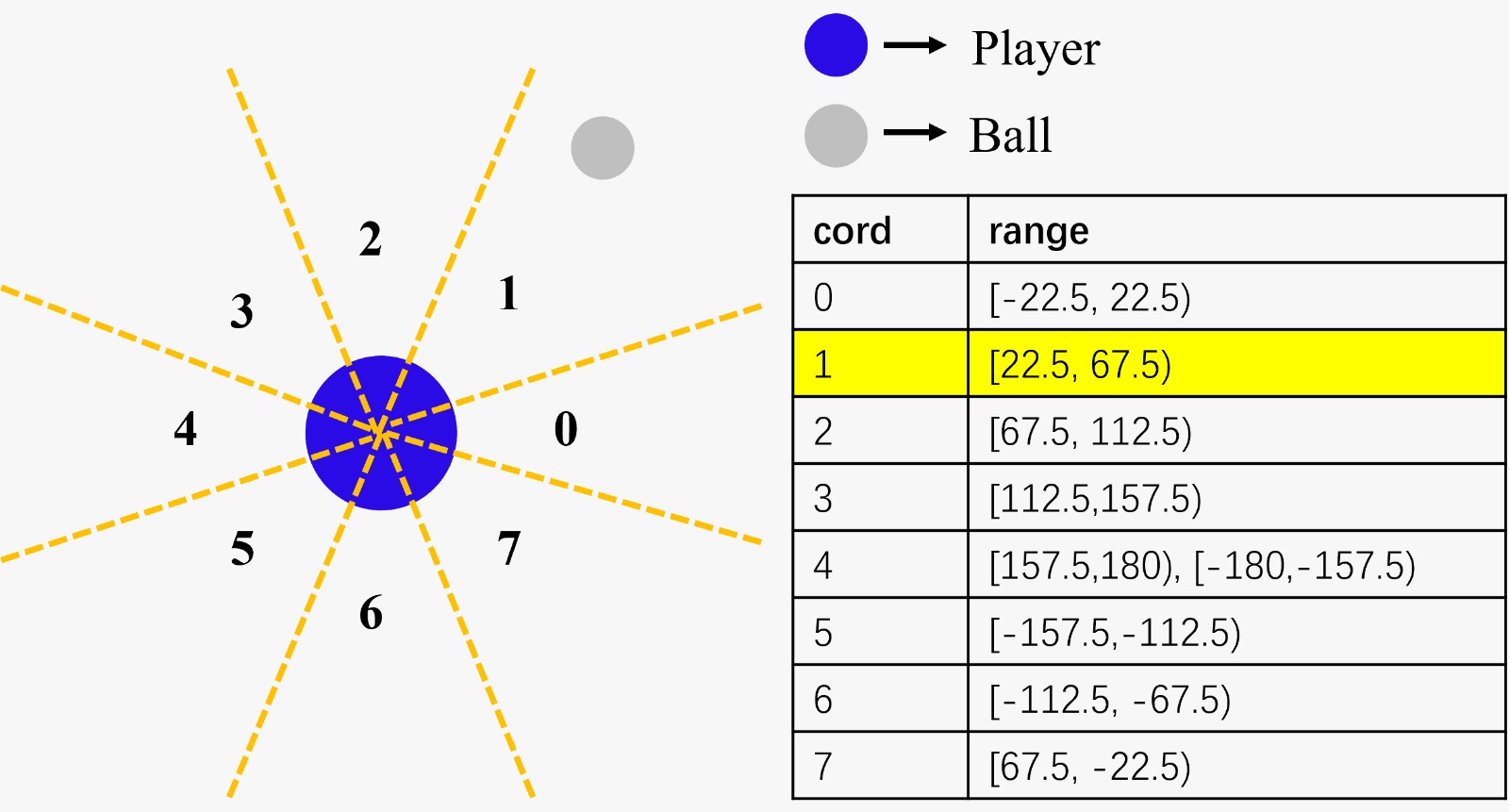
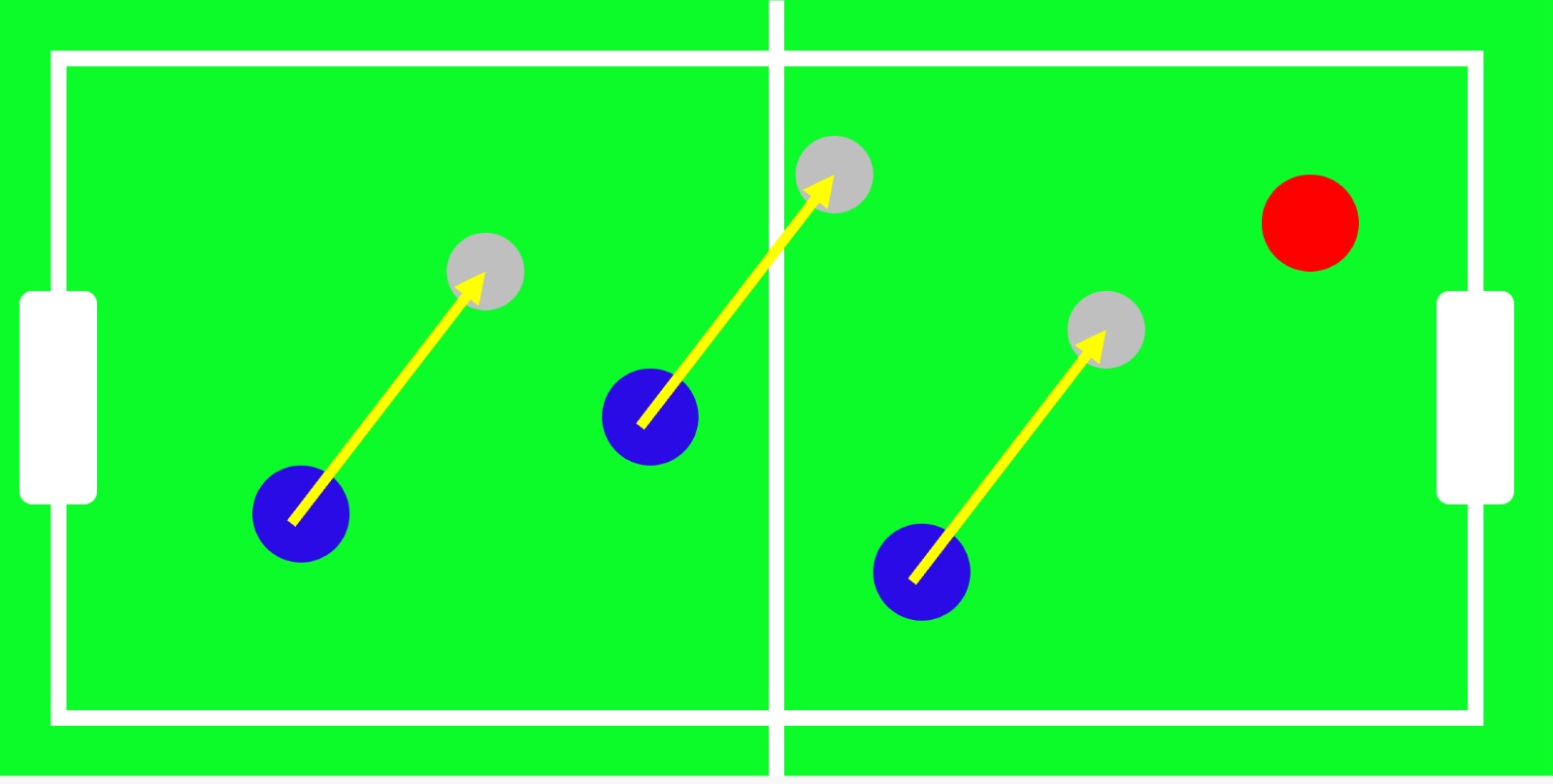
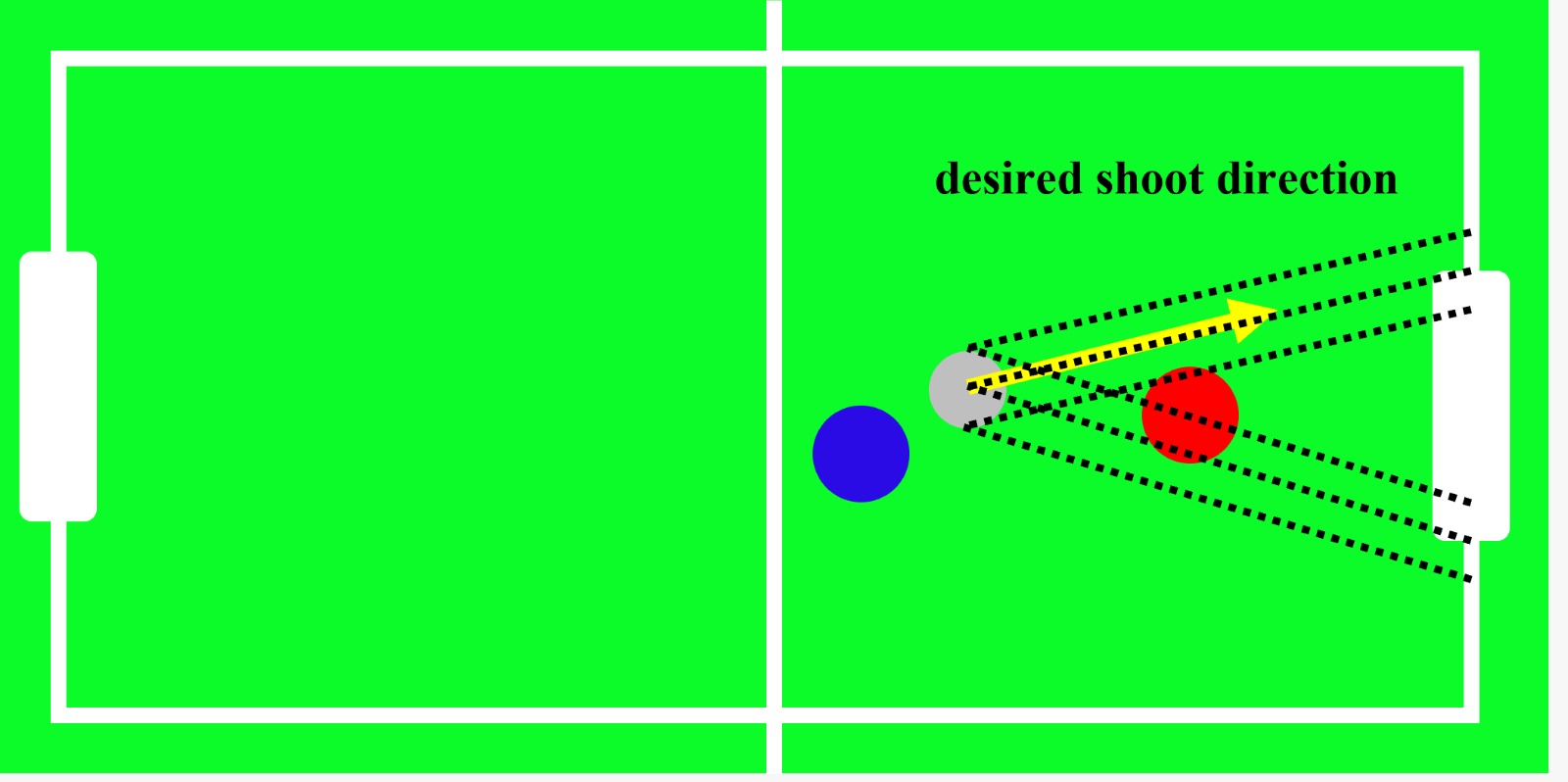
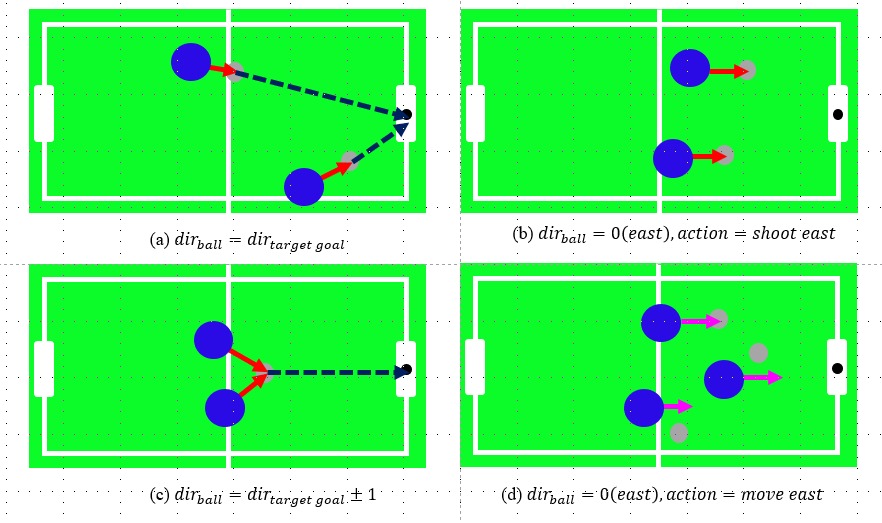
The original states of this Hexball are the x and y positions and velocities of both the agent and the ball in the game. Although the 2D coordinate system is not continuous, it has nearly infinite state combinations due to the many decimal places involved. To address this problem, new states were defined. One represents the distance between the agent and the ball, while the other indicates the direction from the agent to the ball. A Q-table was used to store Q-values for each state based on their indices.
Result Video
Leave a Comment
Your email address will not be published. Required fields are marked *